Spark¶
Кластер¶
Группа компьютеров, объединённых высокоскоростными каналами связи, представляющая с точки зрения пользователя единый аппаратный ресурс.
Кластер - слабо связанная совокупность нескольких вычислительных систем, работающих совместно для выполнения общих приложений, и представляющихся пользователю единой системой
MapReduce¶
MapReduce — это фреймворк для вычисления некоторых наборов распределенных задач с использованием большого количества компьютеров (называемых «нодами»), образующих кластер.
Работа MapReduce состоит из двух шагов: Map и Reduce, названных так по аналогии с одноименными функциями высшего порядка, map и reduce.
На Map-шаге происходит предварительная обработка входных данных. Для этого один из компьютеров (называемый главным узлом — master node) получает входные данные задачи, разделяет их на части и передает другим компьютерам (рабочим узлам — worker node) для предварительной обработки.
На Reduce-шаге происходит свёртка предварительно обработанных данных. Главный узел получает ответы от рабочих узлов и на их основе формирует результат — решение задачи, которая изначально формулировалась.
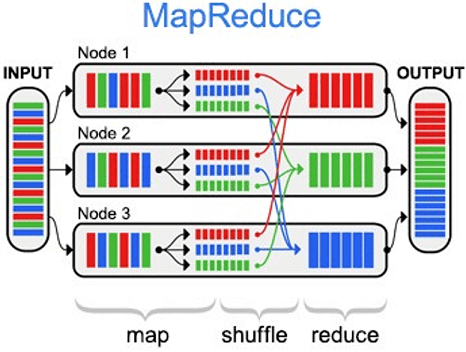
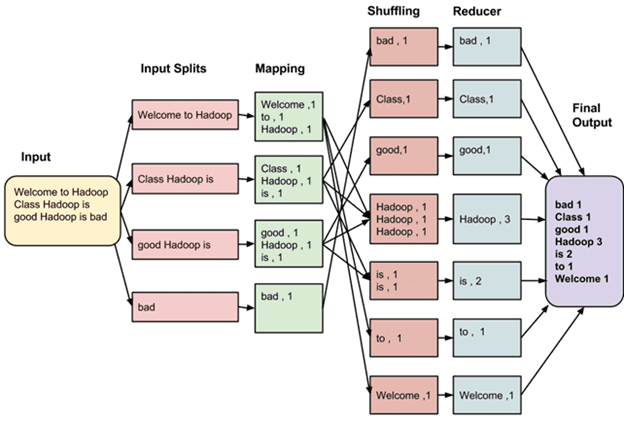
Data locality¶
~ Код распределяется по кластеру и выполняется на всех собранных данных. Паралельно обрабатывает данные и собирается в одно место (mapReduce).
RDD¶
RDD - Resilient Distributed Dataset (Dataset, над которым можно делать преобразования двух типов)
- Dataset
+-Stream. Представляют собой коллекции
- Distrubuted
Распределенные коллекции
- Resilient
Отвечает за востановление данных, при возникновении ошибки на ноде с частью данных
Трансформации¶
Результатом применения данной операции к RDD является новый RDD. Как правило, это операции, которые каким-либо образом преобразовывают элементы данного датасета
map, filter, distinct, union, intersection, cartesian
Действия¶
Применяются тогда, когда необходимо материализовать результат — как правило, сохранить данные на диск, либо вывести часть данных в консоль
saveAsTextFile, collect, take, count, reduce
Dataset¶
Strongly-typed like an RDD, with richer optimizations under the hood
Dataset - распределенная коллекция айтемов, primary abstraction.
Dataset могут быть созданы через Hadoop InputFormats (such as HDFS files) или через преобразование других Dataset.
SparkContext¶
SparkContext - обьект, который отвечает за реализацию более низкоуровневых операций с кластером.
~ Обращение к ResourceManager (при сабмите приложения), смотрит какую конфигурацию нужно задействовать, сколько памяти было передано и тд. Выбирает ноду, являющуюся ApplicationMaster.