Структуры данных¶
Поисковые структуры данных¶
Структура данных реализующая эффективный поиск конкретных элементов множества.
В статическом бинарном дереве поиска не происходит поворотов вокруг ребер. Его оптимальность зависит только от начального положения дерева. Это отличает его от динамического дерева, в котором повороты вокруг ребер разрешены.
Offline дерево поиска получает все запросы сразу и может использовать дополнительную память и вычисления для нахождения наиболее оптимальной последовательности обработки запросов. Стоимость работы дерева поиска для заданной последовательности ключей это стоимость доступа к каждому ключу и модификации дерева, и она не зависит от того, сколько времени мы потратили, чтобы найти оптимальную последовательность.
Online дерево поиска получает следующий запрос, только когда ответит на текущий, соответственно время работы пропорциональное стоимости исполнения запросов. Таким является Splay-дерево.
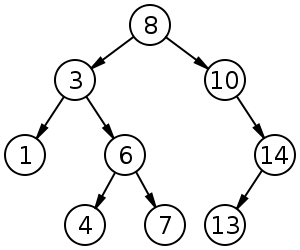
Двоичное дерево поиска¶
Бинарное дерево поиска обладает следующим свойством: если x — узел бинарного дерева с ключом k, то все узлы в левом поддереве должны иметь ключи, меньшие k, а в правом поддереве большие k.
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
n |
n |
n |
n |
АВЛ-дерево¶
Сбалансированное двоичное дерево поиска, в котором поддерживается следующее свойство: для каждой его вершины высота её двух поддеревьев различается не более чем на 1.
|
|
Ссылки:
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
2-3 дерево¶
Структура данных, представляющая собой сбалансированное дерево поиска, такое что из каждого узла может выходить две или три ветви и глубина всех листьев одинакова. Является частным случаем B+-дерево.
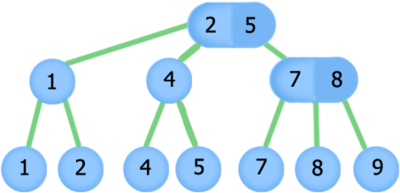
Нелистовые вершины имеют либо два потомка и одно поле, либо три потомка и два поля.
Нелистовая вершина, имеющая двух сыновей, хранит максимум левого поддерева.
Нелистовая вершина, имеющая трех сыновей, хранит два значения: первое значение хранит максимум левого поддерева, второе максимум центрального поддерева.
Все листья лежат на одной глубине
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
B-дерево¶
Сильноветвящееся сбалансированное дерево поиска, позволяющее проводить поиск, добавление и удаление элементов за O(log).
B-дерево является идеально сбалансированным, то есть глубина всех его листьев одинакова.
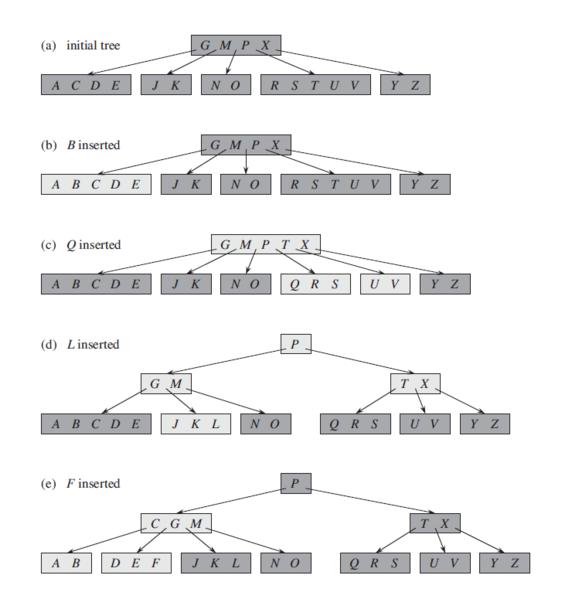
Эффективно для поиска по диску или другому источнику информации считывание с которого можно производить последовательными блоками.
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
B+-дерево¶
В B-дерево во всех вершинах хранятся ключи вместе с сопутствующей информацией. В B+-деревьях вся информация хранится в листьях, а во внутренних узлах хранятся только копии ключей. Таким образом удается получить максимально возможную степень ветвления во внутренних узлах.
Кроме того, листовой узел может включать в себя указатель на следующий листовой узел для ускорения последовательного доступа, что решает одну из главных проблем B-деревьев.

Удаление значений из B+ дерева (схожее при этом с 2-3 деревом, кроме последовательностей листьев и хранения не максимума левого поддерева, а минимума правого)¶
Ссылки:
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
Красно-черное дерево¶
Сбалансированное двоичное дерево поиска, в котором баланс осуществляется на основе “цвета” узла дерева, который принимает только два значения: “красный” (англ. red) и “чёрный” (англ. black). При этом все листья дерева являются фиктивными и не содержат данных, но относятся к дереву и являются чёрными. Для экономии памяти фиктивные листья можно сделать одним общим фиктивным листом.
Каждый узел промаркирован красным или чёрным цветом:
Корень и конечные узлы (листья) дерева — чёрные.
У красного узла родительский узел — чёрный.
Чёрный узел может иметь чёрного родителя.
Все простые пути из любого узла x до листьев содержат одинаковое количество чёрных узлов.
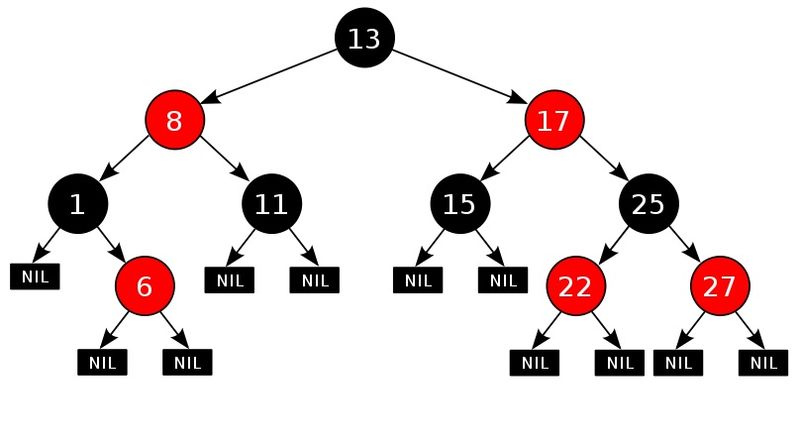
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
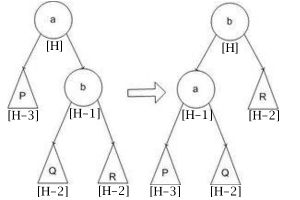
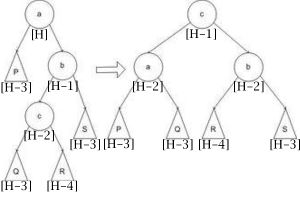
Вставка элемента¶
Вставляется узел, так-же как и в двоичное дерево поиска, при этом он окрашен в красный цвет, так же к нему добавляется 2 конечных черных узла (NIL). Так как узел красный баланс черной высоты не нарушается.
Если родительский узел вставляемого узла - черный:
Ничего перекрашивать не надо, так как все условия существования дерева соблюдены.
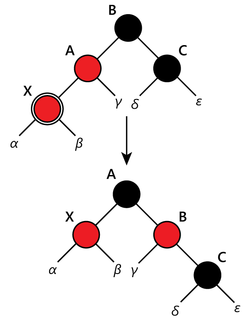
Если родительский узел вставляемого узла - красный, есть два случая решения проблемы двух красных узлов (в зависимости от узла дяди):
Поворот поддерева
Перекраска поддерева
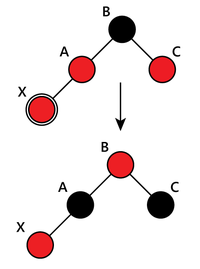
При перекраске поддерева процесс повторяется для всех родительских узлов пока условие валидности не будет достигнуто.
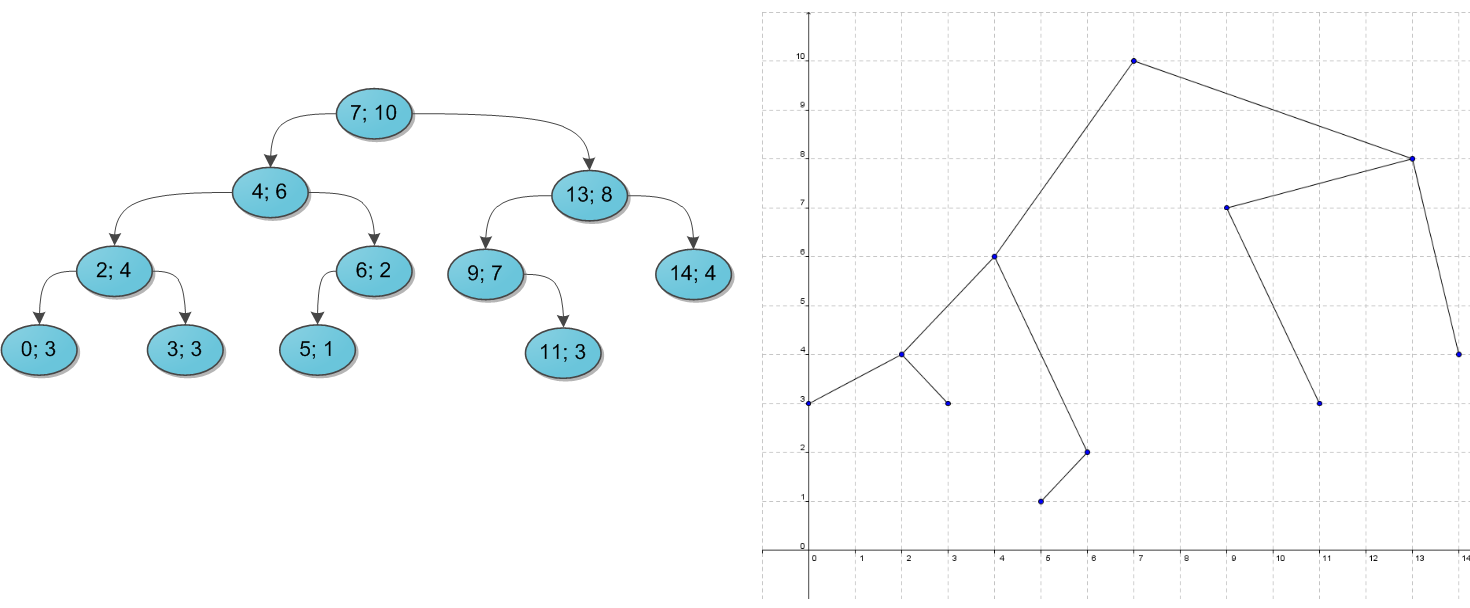
Декартово дерево¶
Позволяет хранить и искать координаты на декартовой плоскости.
Если рисовать бинарное дерево на плоскости, ключ будет соответствовать x-координате вершины (за счет упорядоченности).
Тогда можно ввести и y-координату (назавем ее высотой), которая будет обладать следующим свойством: высота вершины больше высоты детей (heap).
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
n |
n |
n |
n |
Splay-дерево¶
Двоичное дерево позволяет находить быстрее те данные, которые использовались недавно, за счёт перемещения к корню. Относится к разряду сливаемых деревьев.
Ссылки:
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
n |
n |
n |
n |
Список с пропусками¶
Вероятностная структура данных, позволяющая в среднем за O(log(n)) времени выполнять операции добавления, удаления и поиска элементов.
Список с пропусками состоит из нескольких уровней, на каждом из которых находится отсортированный связный список. На самом нижнем (первом) уровне располагаются все элементы. Дальше около половины элементов в таком же порядке располагаются на втором, почти четверть — на третьем и так далее, но при этом известно, что если элемент расположен на уровне i, то он также расположен на всех уровнях, номера которых меньше i.
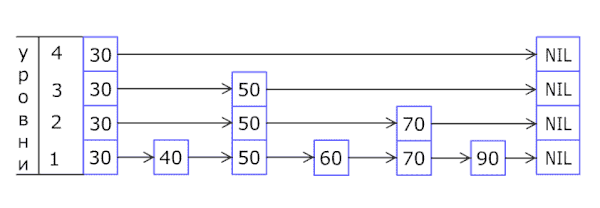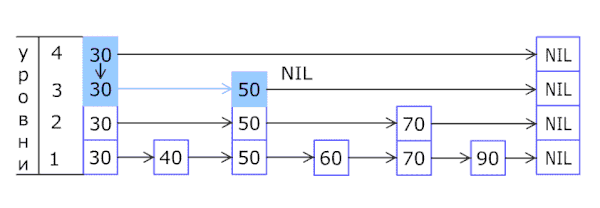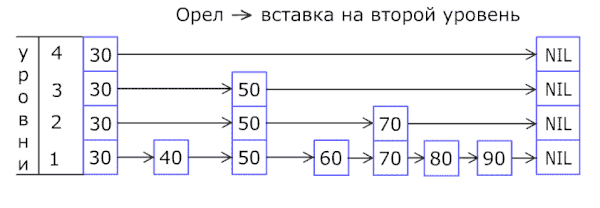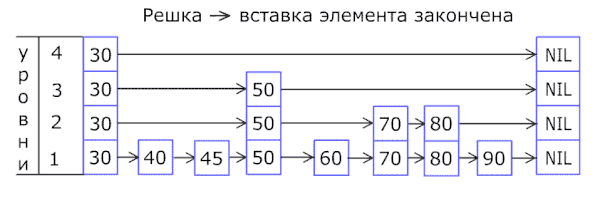
Insert |
Delete |
Search |
Память |
|---|---|---|---|
log(n) |
log(n) |
log(n) |
n |
n |
n |
n |
n |
Цифровой бор¶
Цифровой бор, Быстрый цифровой бор, Сверхбыстрый цифровой бор
Бор, в котором в качестве строк используются двоичные записи чисел, включая ведущие нули.
Tango-дерево¶
Online бинарное дерево поиска.
Рассмотрим бинарное дерево поиска. Изначально сделаем все левые ребра жирными. Разобьем наше дерево на жирные пути.
Жирный путь (англ. Prefered path) — максимальный по включению путь, состоящий из жирных ребер.
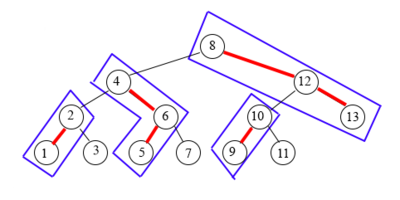
Каждый из этих жирных путей организуем в свое splay-дерево. Splay-дерево может быть построено как угодно.
Из каждой вершины каждого splay-дерева создадим вспомогательную ссылку на корень другого splay-дерева, в котором лежит ее ребенок, связанный с ней нежирным ребром в исходном бинарном дереве поиска (при этом ссылка ставится на само дерево, а не на ребенка).
Корнем tango-дерева будет являться splay-дерево, которое есть жирный путь от корня исходного бинарного дерева поиска.
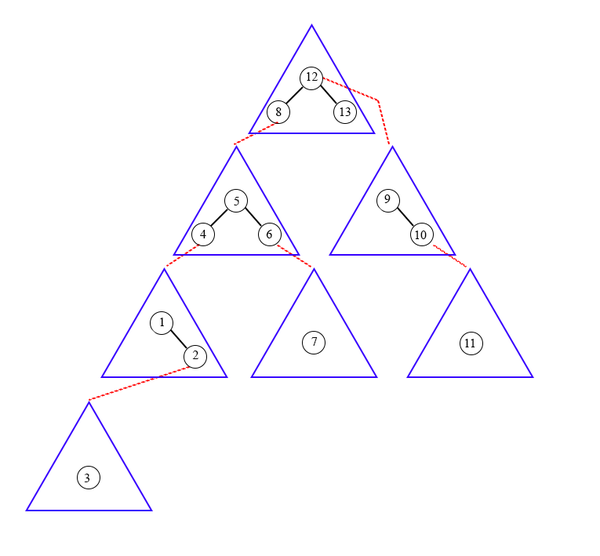
Note
Таким образом, все наши ключи организуют иерархичную структуру — Tango-дерево.
Каждый жирный путь — splay-дерево, и каждая вершина дерева указывает на корень другого splay-дерева, в котором лежит сын вершины по нежирному ребру.
Глубина tango-дерева \(log(n)\)
Общее время работы дерева \(( M + K ) ⋅ log(log(n))\), где \(K\) — число изменений жирных ребер, \(M\) — число запросов.
Операций первого становления ребра жирным — \(O(log(n))\), это дает несущественный вклад в асимптотику.
Поиск элемента¶
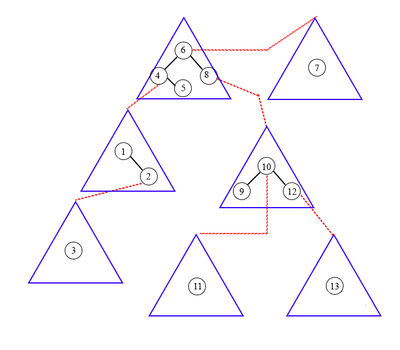
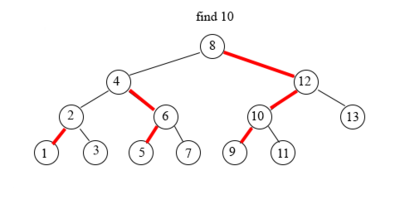
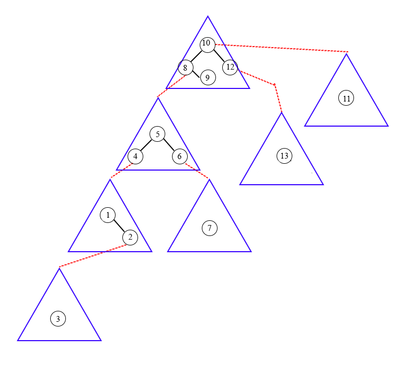
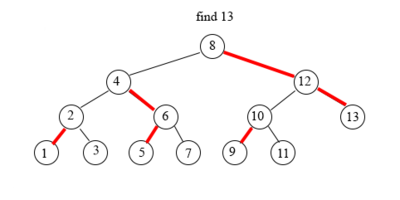
Поиск элемента в tango-дереве схож с поиском в обычном дереве поиска.
Начинаем с поиска в жирном пути корня tango-дерева — splay-дереве.
Если текущий жирный путь не содержит искомый элемент, то сделаем переход по вспомогательной ссылке (красная стрелка в tango-дереве) и осуществим поиск в новом жирном пути (splay-дереве).
Note
Поиск в splay-дереве (синее дерево в splay-дереве) работает за высоту от количества вершин (количество вершин — длина жирного пути (\(log(n)\))) — то есть за \(log(log(n))\)
Поиск во всем дереве соответствует (\(log(log(n))\))⋅ число проходов по нежирному ребру.
Пример
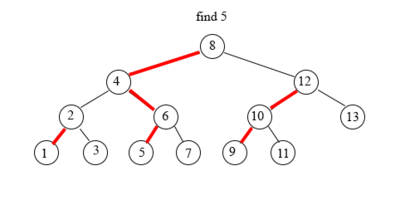
|
|
|
|
|
1.png)
|
Приоритетные очереди¶
Абстрактная структура данных наподобие стека или очереди, где у каждого элемента есть приоритет. Элемент с более высоким приоритетом находится перед элементом с более низким приоритетом.
Обычно приоритетные очереди реализуются с помощью куч.
Двоичная куча¶
Двоичная куча - Такое двоичное дерево, для которого выполнены три условия:
Значение в любой вершине не меньше, чем значения её потомков.
Глубина листьев (расстояние до корня) отличается не более чем на 1 слой.
Последний слой заполняется слева направо.
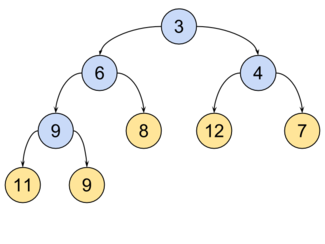
Пример кучи для минимума¶
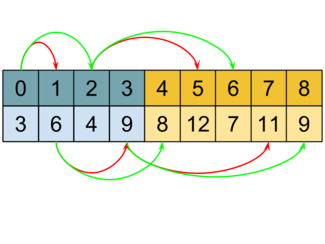
Хранение кучи в массиве, красная стрелка — левый сын, зеленая — правый¶
Найти |
Удалить |
Добавить |
Уменьшить |
Слияние |
|---|---|---|---|---|
Θ(1) |
Θ(log n) |
Θ(log n) |
Θ(log n) |
Θ(n) |
Базовые процедуры¶
Восстановление свойств кучи
siftDownЕсли значение измененного элемента увеличивается, то свойства кучи восстанавливаются функцией
siftDown.Работа процедуры: если i-й элемент меньше, чем его сыновья, всё поддерево уже является кучей, и делать ничего не надо. В противном случае меняем местами i-й элемент с наименьшим из его сыновей, после чего выполняем
siftDownдля этого сына. Процедура выполняется за время \(O(log(n))\).siftUpЕсли значение измененного элемента уменьшается, то свойства кучи восстанавливаются функцией
siftUp.Работа процедуры: если элемент больше своего отца, условие 1 соблюдено для всего дерева, и больше ничего делать не нужно. Иначе, мы меняем местами его с отцом. После чего выполняем
siftUpдля этого отца. Иными словами, слишком маленький элемент всплывает наверх. Процедура выполняется за время \(O(log(n))\)
Извлечение минимального элемента
Выполняет извлечение минимального элемента из кучи за время \(O(log(n))\). Извлечение выполняется в четыре этапа:
Значение корневого элемента (он и является минимальным) сохраняется для последующего возврата.
Последний элемент копируется в корень, после чего удаляется из кучи.
Вызывается
siftDownдля корня.Сохранённый элемент возвращается.
Пример извлечения минимального элемента
Здесь извлечение происходит не через siftDown, и лишь демонстрирует общий концепт удаления минимума.
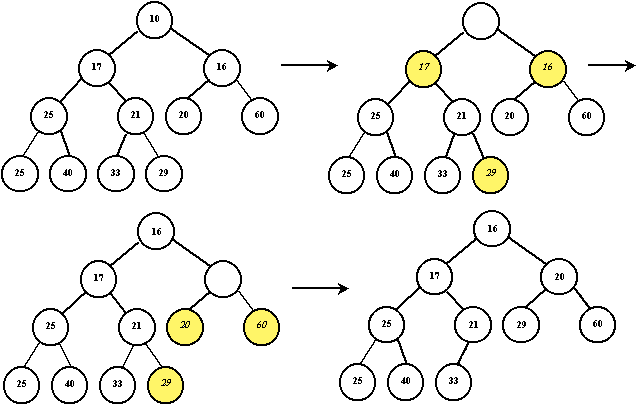
Добавление нового элемента
Выполняет добавление элемента в кучу за время \(O(log(n))\).
Добавление произвольного элемента в конец кучи, и восстановление свойства упорядоченности с помощью процедуры siftUp.
Персистентные структуры данных¶
Структуры данных, которые при внесении в них каких-то изменений сохраняют все свои предыдущие состояния и доступ к этим состояниям.
Персистентный стек¶
push(x, i)Создает новый элемент со значением x, который ссылается на элемент с номером i как на предыдущий элемент в стеке.
pop(i)Возвращает значение, хранящееся в элементе с номером i и копирует элемент, предыдущий для него.
Способ использования:
Изначально есть один пустой стек:

push(1, 5):

Создается новая вершина со значением 5, ссылающаяся на 1-ую
push(2, 10) и push(1, 6):

Все 4 стека сейчас верно построены и легко восстанавливаются.
pop(2):

Возвращает 5 и копирует 1-ую вершину. Результирующий пятый стек — пустой.
pop(3):

pop(3) возвращает 10 и копирует 2-ую вершину. Результат: шестой стек.
Ссылки:
Бор (Префиксное дерево)¶
Структура данных для хранения набора строк, представляющая из себя подвешенное дерево с символами на рёбрах.
Строки получаются последовательной записью всех символов, хранящихся на рёбрах между корнем бора и терминальной вершиной.
Размер бора линейно зависит от суммы длин всех строк, а поиск в бору занимает время, пропорциональное длине образца.
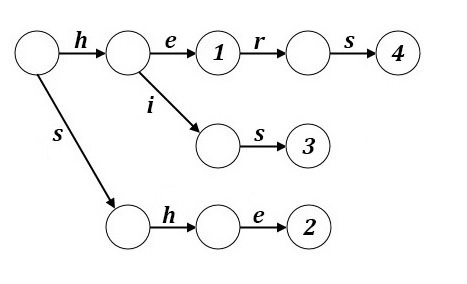
Бор для набора образцов {he, she, his, hers}¶